Combining both n-grams and random forest models to detect malicious activity.
Author: Haroen Bashir
An essential part of Managed Detection and Response at Fox-IT is the Security Operations Center. This is our frontline for detecting and analyzing possible threats. Our Security Operations Center brings together the best in human and machine analysis and we continually strive to improve both. For instance, we develop machine learning techniques for detecting malicious content such as DGA domains or unusual SMB traffic. In this blog entry we describe a possible method for random filename detection.
During traffic analysis of lateral movement we sometimes recognize random filenames, indicating possible malicious activity or content. Malicious actors often need to move through a network to reach their primary objective, more popularly known as lateral movement [1].
There is a variety of routes for adversaries to perform lateral movement. Attackers can use penetration testing frameworks such as Metasploit [3] or Microsoft Sysinternal application PsExec. This application creates the possibility for remote command execution over the SMB protocol [4].
Due to its malicious nature we would like to detect lateral movement as quickly as possible. In this blogpost we build on our previous blog entry [2] and we describe how we can apply the magic of machine learning in detection of random filenames in SMB traffic.
Supervised versus unsupervised detection models
Machine learning can be applied in various domains. It is widely used for prediction and classification models, which suits our purpose perfectly. We investigated two possible machine learning architectures for random filename detection.
The first detection method for random filenames is set up by creating bigrams of filenames, which you can find more information about in our previous post [2]. This detection method is based on unsupervised learning. After the model learns a baseline of common filenames, it can now detect when filenames don’t belong in its learned baseline.
This model has a drawback; it requires a lot of data. The solution can be found with supervised machine learning models. With supervised machine learning we feed a model data whilst simultaneously providing the label of the data. In our current case, we label data as either random or not-random.
A powerful supervised machine learning model is the random forest. We picked this architecture as it’s widely used for predictive models in both classification and regression problems. For an introduction into this technique we advise you to see [4]. The random forest is based on multiple decision trees, increasing the stability of a detection model. The following diagram illustrates the architecture of the detection model we built.
Similar to the first model, we create bigrams of the filenames. The model cannot train on bigrams however, so we have to map the bigrams into numerical vectors. After training and testing the model we then focus on fine-tuning hyperparameters. This is essential for increasing the stability of the model. An important hyperparameter of the random forest is depth. A greater depth will create more decision splits in the random forest, which can easily cause overfitting. It is therefore highly desirable to keep the depth as low as possible, whilst simultaneously maintaining high precision rates.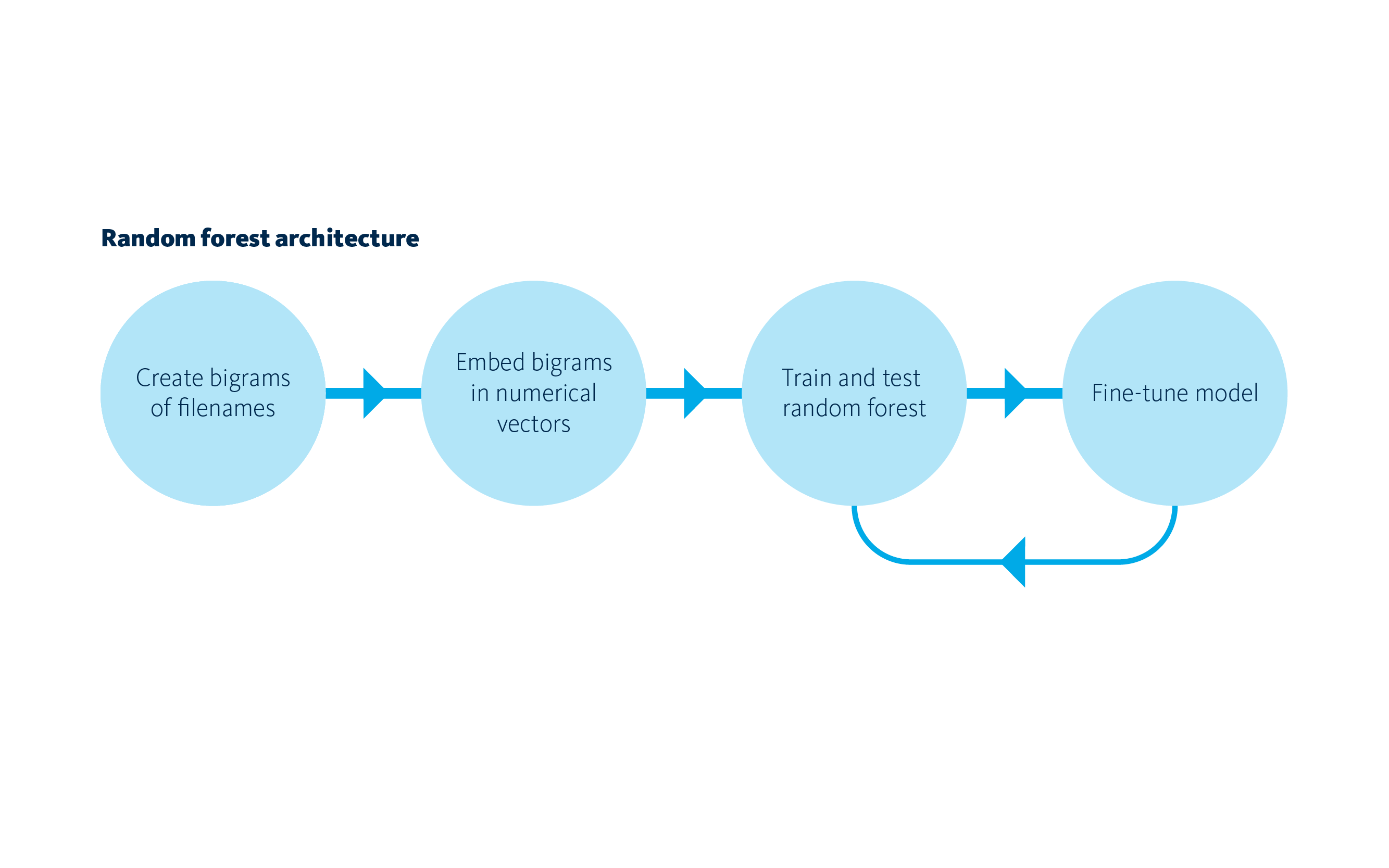 Results
Results
Proper data is one of the most essential parts in machine learning. We gathered our data by scraping nearly 180.000 filenames from SMB logs of our own network. Next to this, we generated 1.000 random filenames ourselves. We want to make sure that the models don’t develop a bias towards for example the extension “.exe”, so we stripped the extensions from the filenames.
As we stated earlier the bigrams model is based on our previously published DGA detection model. This model has been trained on 90% percent of filenames. It is then tested on the remaining filenames and 100% of random filenames.
The random forest has been trained and tested in multiple folds, which is a cross validation technique[6]. We evaluate our predictions in a joint confusion matrix which is illustrated below.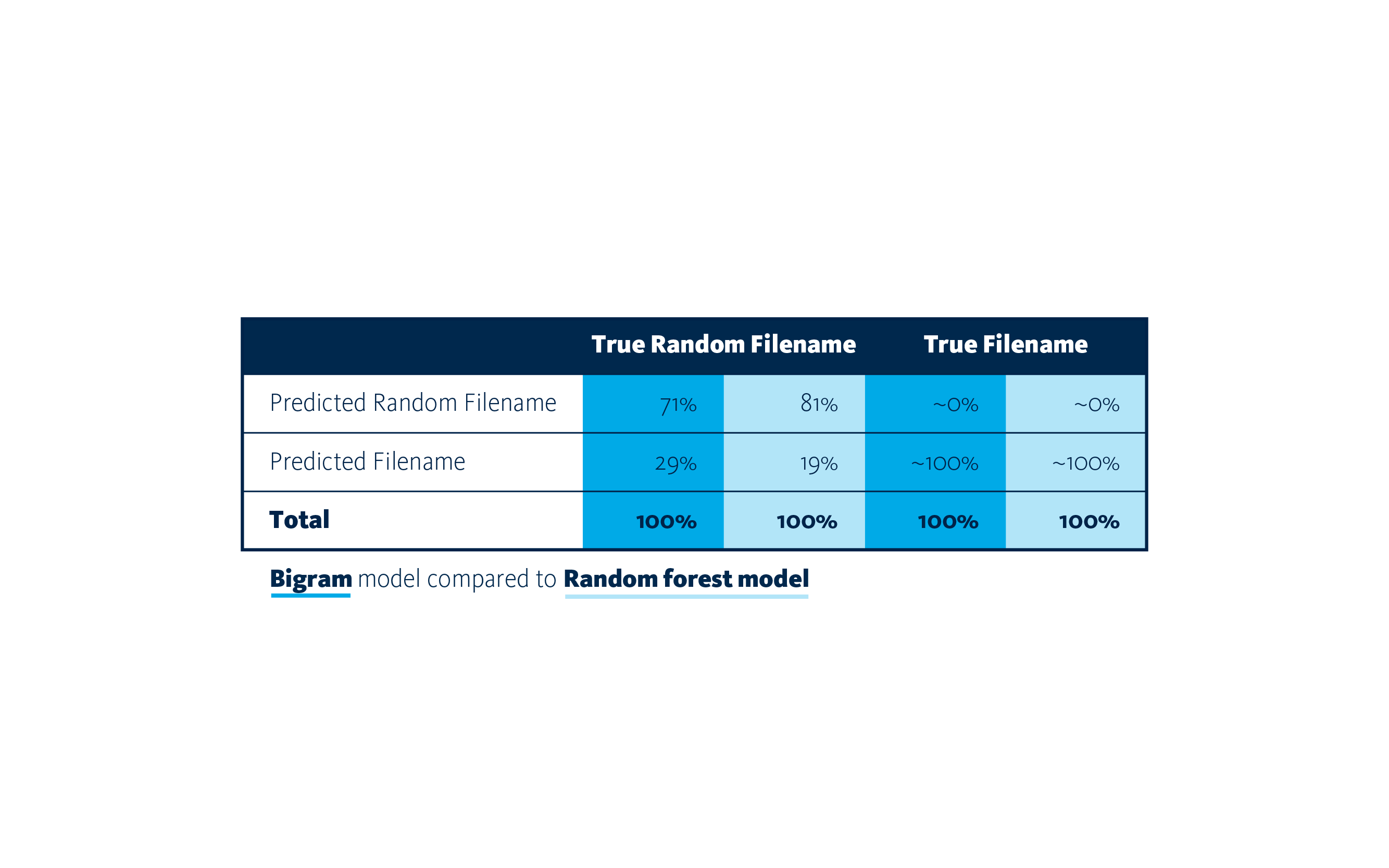
True positives are shown in the upper right column, the bigrams model detected 71% of random filenames and the random forest detected 81% of random filenames. As you can see the models produce low false positive rates, in both models ~0% of not random filenames have been incorrectly classified as random. This is great for use in our Security Operations Center, as this keeps the workload on the analysts consistent.
The F1-scores are 0.83 and 0.89 respectively. Because we focus on adding detection with low false positive rates, it is not our priority to reduce the false negative rates. In future work we will take a better look at the false negative rates of the models.
We were quite interested in differences in both detection models. Looking at the visualization below we can observe that both models equally detect 572 random filenames. They separately detect 236 and 141 random filenames respectively. The bigrams model might miss more random filenames due to its unsupervised architecture. It is possible that the bigrams model requires more data to create it’s baseline and therefore doesn’t perform as well as the supervised random forest.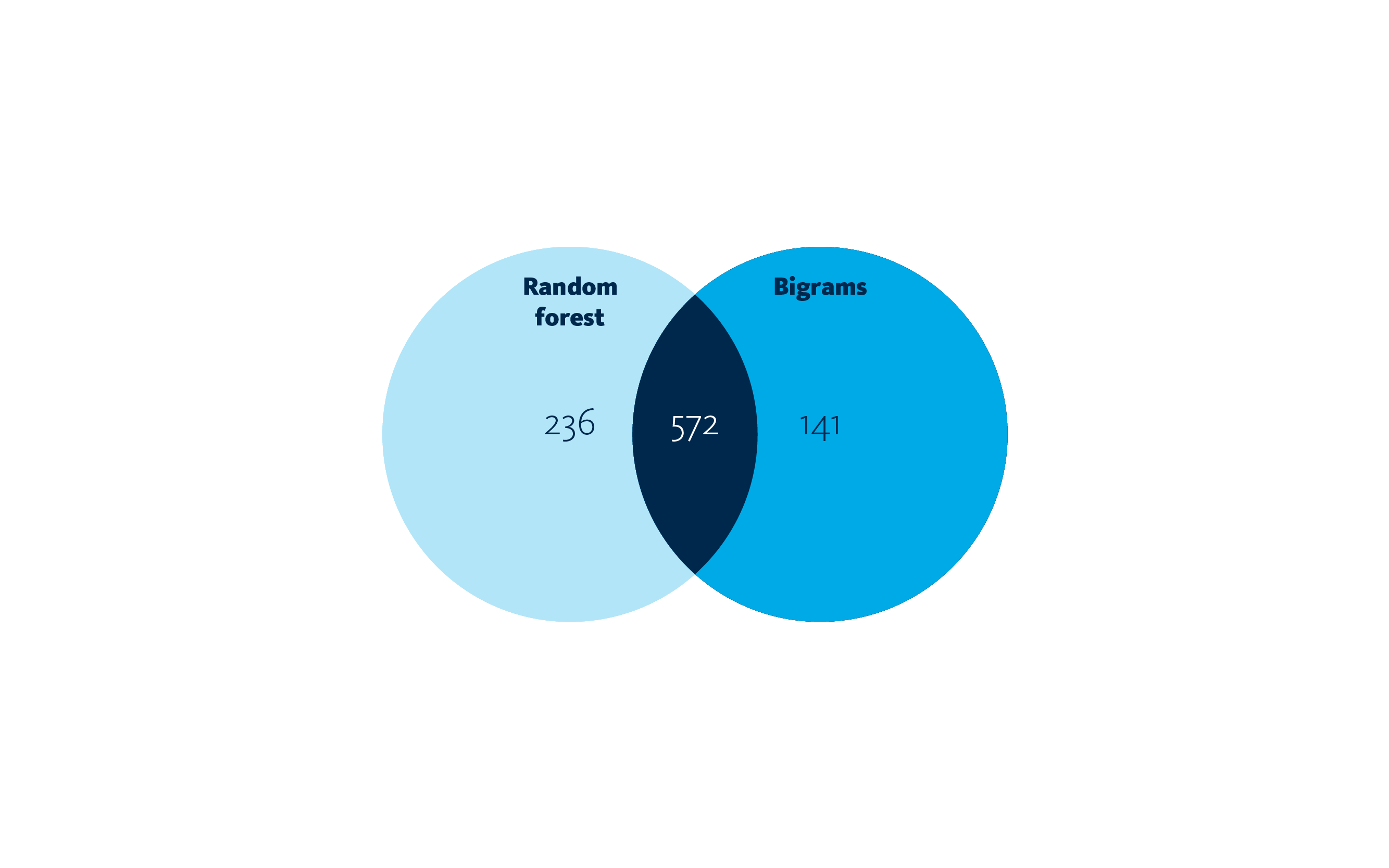 The overlap in both models and the low false positive rate gave us the idea to run both these models cooperatively for detection of random filenames. It doesn’t cost much processing and we would gain a lot! In practical setting this would mean that if a random filename slips by one detection model, it is still possible for the other model to detect this. In theory, we detect 90% of random filenames! The low false positive rates and complementary aspects of the detection models indicate that this setup could be really useful for detection in our Security Operations Center.
The overlap in both models and the low false positive rate gave us the idea to run both these models cooperatively for detection of random filenames. It doesn’t cost much processing and we would gain a lot! In practical setting this would mean that if a random filename slips by one detection model, it is still possible for the other model to detect this. In theory, we detect 90% of random filenames! The low false positive rates and complementary aspects of the detection models indicate that this setup could be really useful for detection in our Security Operations Center.
Conclusion
During traffic analysis in our Security Operations Center we sometimes recognize random filenames, indicating possible lateral movement. Malicious actors can use penetration testing frameworks (e.g. Metasploit) and Microsoft processes (e.g. PsExec) for lateral movement. If adversaries are able to do this, they can easily compromise a (sub)network of a target. Needless to say that we want to detect this behavior as quickly as possible.
In this blog entry we described how we applied machine learning in order to detect these random filenames. We showed two models for detection: a bigrams model and a random forest. Both these models yield good results in testing stage, indicated by the low false positive rates. We also looked at the overlap in predictions from which we concluded that we can detect 90% of random filenames in SMB traffic! This gave us the idea to run both detection models cooperatively in our Security Operations Center.
For future work we would like to research the usability of these models on endpoint data, as our current research is solely focused on detection in network traffic. There is for instance lots of malware that outputs random filenames on a local machine. This is just one of many possibilities which we can better investigate.
All in all, we can confidently conclude that machine learning methods are one of many efficient ways to keep up with adversaries and improve our security operations!
References
[1] – https://attack.mitre.org/tactics/TA0008/
[2] – https://blog.fox-it.com/2019/06/11/using-anomaly-detection-to-find-malicious-domains.
[3] – https://www.offensive-security.com/metasploit-unleashed/pivoting/
[4] – https://www.mindpointgroup.com/blog/lateral-movement-with-psexec/
[5] – https://medium.com/@williamkoehrsen/random-forest-simple-explanation-377895a60d2d
[6] – https://towardsdatascience.com/why-and-how-to-cross-validate-a-model-d6424b45261f
